在Python中实现Johansen Test for Cointegration
在这篇博文中,您将了解Johansen Test的协整本质,并学习如何在Python中实现它。另一种流行的协整检验是Augmented Dickey-Fuller(ADF)检验。ADF测试具有使用Johansen测试克服的限制。
ADF测试使人们能够测试两次系列之间的协整。Johansen测试可用于检查最多12次系列之间的协整。这意味着可以使用两个以上的时间序列创建固定的线性资产组合,然后可以使用平均回复策略进行交易,如对交易,三联交易,指数套利和长短投资组合。要了解有关这些策略的更多信息,请参阅EP Chan博士的Python平均回复策略课程。
其次,ADF测试给出了改变两次序列顺序的不同结果。使用Johansen Test可以克服这个问题,因为它与订单无关。现在让我们看看约翰森测试背后的数学。
约翰森测试背后的数学
Johansen测试基于时间序列分析。ADF测试基于自回归模型,时间序列中的值在同一时间序列的先前值上回归。当存在多个变量时,您仍然可以将当前价格的关系写为自回归模型中过去价格的线性函数,但更准确地说,此模型称为矢量误差修正模型(VECM)。下面给出的是VECM的等式。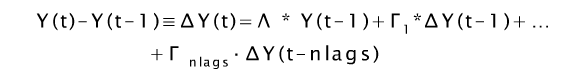
在这个等式中,我们有多维变量,因此乘法将是矩阵乘法。因此,该等式中的每个滞后项的系数是矢量项。
在Johansen测试中,我们检查lambda是否具有零特征值。当所有特征值都为零时,这意味着该序列不是协整的,而当某些特征值包含负值时,则意味着可以创建时间序列的线性组合,这将导致平稳性。
这些价格的线性组合代表了投资组合的净市值。如果投资组合价值的变化通过负回归系数与其当前值相关,或者在这种情况下是负特征值,那么我们将得到平均回复或固定投资组合。这是Johansen Test的精髓。
约翰逊测试的Python实现
现在让我们在Python上用一对资产实现Johansen Test,这里我们以GLD-GDX对为例,GLD是SPDR Gold Trust ETF,GDX是Gold Miners ETF。我们可以预期这两种资产是相关的,我们现在将检查这些资产是否是协整的,如果这样我们就可以在这对资产上建立一对交易策略,这将证明是有利可图的。完成下面提到的代码:
我们将从导入两个库开始。要导入的第一个库是Pandas库,它将用于从CSV文件中读取数据,然后创建包含两个仪器数据的数据框。
其次,我们将从Johansen库中导入coint_johansen函数,这是由托莱多大学经济系的James LeSage开发的函数。您可以从此处下载此代码。
导入库后,我们通过读取csv文件中的数据,将两个证券的数据存储在变量df_x和df_y中。接下来,我们创建一个数据框df,它存储我们必须运行Johansen测试的两次系列。
然后,我们通过将存储时间序列数据(df),0和1的数据帧作为其三个参数传递来调用coint_johansen函数。参数中的第二项表示零假设的顺序,值0表示它是常数项,多项式中没有时间趋势。第三项指定计算估算器时使用的滞后差项的数量,这里我们使用单个滞后差项。
该测试的输出为我们提供了跟踪统计和特征统计。

跟踪统计信息告诉我们特征值的总和是否为0.零假设r <= 0给出了17.895的跟踪统计量,因此零假设可以在95%置信水平下被拒绝,因为跟踪的幅度统计值大于临界值,请注意Johansen测试仅给出输出的大小,因此我们不必担心这些迹象。
特征统计量以特征值递减的顺序存储特征值,它们告诉我们系列的协整程度如何强烈,或者意味着恢复的趋势有多强。在我们的例子中,零假设的特征统计量可以在95%置信水平下被拒绝,因为17.5694大于14.2639。
特征向量给出了时间序列的均值回复线性组合的等式。对应于最高特征值的特征向量表示具有最大均值回复特性的投资组合。零假设是时间序列不是协整的,因此当我们拒绝零假设并接受替代假设时,我们建议该序列是协整的。
约翰森测试的性质
即使时间序列的顺序颠倒,Johansen测试也会给出相同的结果,您可以尝试将其作为练习。该测试可用作检查协整的与订单无关的方式。这个测试允许我们检查三胞胎,四胞胎之间的协整,最多12个系列。
原因很简单,没有数学家能够计算超过12个变量的临界值。因此,结果不能用于拒绝零假设。矢量误差校正模型可以用于甚至1000种股票,具体取决于计算能力的可用性。它无法判断股票是否正在协整,但它仍然可以用作预测模型。